Trascripción del articulo de la Revista Harvard Deusto Noviembre 2021 por considerarlo de interés
Ernest Solé – Susana Domingo
Business Review (Núm. 316) · TIC · Noviembre 2021
La utilización de la inteligencia artificial en las empresas ha empezado a cobrar fuerza hace poco. Uno de los motivos es que son muchos los desafíos a la hora de emplear esta tecnología de forma exitosa: contar con una buena arquitectura de información, establecer una estrategia coherente, encontrar la tecnología óptima, la incerteza de no saber cómo funciona exactamente cada proceso o el rechazo que provoca en algunas personas son algunos ejemplos.
La implementación y el uso de aplicaciones de inteligencia artificial en las empresas, a pesar de ofrecer un enorme potencial, tienen por delante un largo y complejo camino que recorrer. ¿Cuáles son los principales desafíos a los que se debe hacer frente?
En 1954, en plena Guerra Fría, IBM desarrolló su primer traductor automático ruso-inglés. Este sistema pionero tenía algunas limitaciones: operaba con solamente seis reglas gramaticales y un diccionario de doscientas cincuenta palabras. A pesar de ello, logró traducir sesenta frases. Dos años más tarde, el equipo de investigadores de Stanford liderado por John McCarthy enfrentó una máquina a dos campeones de ajedrez rusos, perdiendo dos partidas, pero empatando otras dos. Fue este equipo, precisamente, el que acuñó la expresión inteligencia artificial, que definió como “la ciencia e ingeniería de hacer máquinas inteligentes, especialmente programas inteligentes”.
¿Programas inteligentes? ¿Estamos hablando, sencillamente, de un tipo de software más avanzado? Una de las posibles respuestas a esta pregunta, según el investigador de la Universidad de Aalto Antti Ajanki, es que, en el entorno de los programas informáticos, los programadores automatizan tareas escribiendo programas, mientras que, en el entorno de la inteligencia artificial, es la computadora la que escribe el programa que se ajusta a los datos disponibles. Esta última afirmación puede parecer exagerada; la aplicación de inteligencia artificial no escribe el programa desde cero, puesto que ha sido desarrollada por un programador, pero lo que sí hace es aprender patrones de modo autónomo, en función de datos que recibe y procesa.
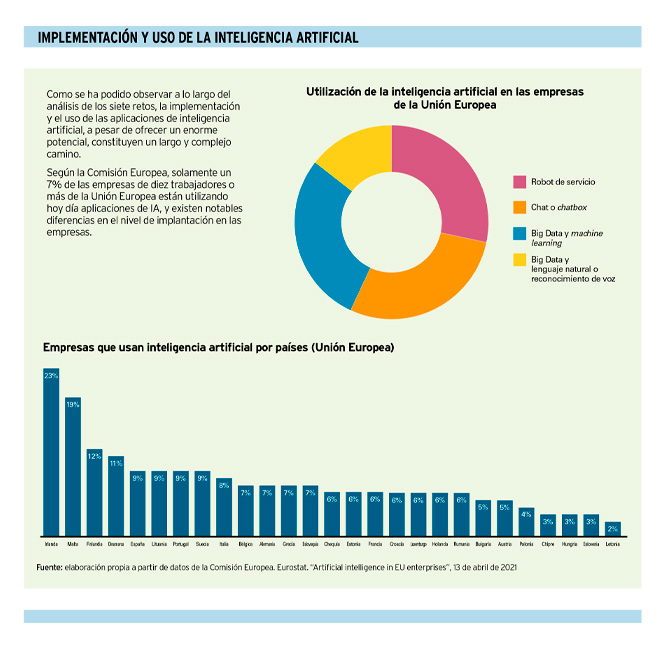
La inteligencia artificial en las empresas
La inteligencia artificial aporta un gran valor a aquellas compañías que la utilizan de forma apropiada, incrementando la eficiencia y la calidad de sus operaciones, de una forma que implica cambios radicales en la gestión empresarial en todas sus áreas: logística, operaciones, marketing, ventas, finanzas, etc. Algunos consideran que esta es una tecnología disruptiva, por la forma en la que está influyendo y cambiando un gran número de actividades empresariales, institucionales, científicas, tecnológicas y personales.
Si McCarthy habló de inteligencia artificial por primera vez hace sesenta y cinco años, debe haber alguna razón por la que esta tecnología no haya irrumpido con fuerza hasta hace relativamente poco tiempo. El motivo, entre otros, lo podemos encontrar en el hecho de que las aplicaciones de inteligencia artificial son más eficaces cuanto mayor es la cantidad y mejor la calidad de datos a procesar. El continuo incremento de la potencia de procesamiento de los ordenadores, la generalización del uso de Internet, la creación de una gran cantidad de bases de datos y el acceso a ellas han permitido los impresionantes avances de estas aplicaciones en los últimos años. Aun así, las empresas que deseen implementar la inteligencia artificial en su día a día, se enfrentan a varios retos.
Primer reto: Arquitectura de Información (AI)
Basura dentro, basura fuera. Este es un mantra habitual en la industria de la inteligencia artificial, que sugiere que unos datos de mala calidad, tras ser procesados por una aplicación de inteligencia artificial, ofrecen un resultado de mala calidad. Cantidad y calidad no van de la mano, más bien están reñidas. Por lo tanto, un primer reto al que enfrentarse en el uso de datos es que, además de obtenerlos en cantidad suficiente, estos sean de calidad también suficiente. Otra dificultad a la que puede enfrentarse la empresa a la hora de utilizar los datos es el hecho de que, frecuentemente, la información de la empresa está almacenada en silos, es decir, en repositorios de datos separados y no interconectados ni compatibles, y no está, por tanto, preparada para ser procesada por una aplicación de inteligencia artificial.
A todo ello, no se puede explotar eficazmente una aplicación de inteligencia artificial (IA) sin contar con una buena arquitectura de información (AI). Dicho de otro modo, no hay buena IA sin una adecuada AI.
Este concepto de “arquitectura de información” queda muy bien explicado en el método desarrollado por el vicepresidente sénior de IBM Rob Thomas, denominado escalera de inteligencia artificial. En base a este método, es necesario modelar el conjunto de datos disponibles en una plataforma única y pasar sucesivamente por los cuatro escalones de la escalera:
1) Recoger datos, haciéndolos simples y accesibles.
2) Organizar los datos para crear las bases analíticas, listas para ser procesadas.
3) Analizar los datos para comprobar su veracidad y transparencia. Los datos deben ser correctos y, a ser posible, sin sesgos.
4) Desplegar las aplicaciones de AI en la empresa.
Es frecuente que una empresa joven carezca de una base de datos con la que utilizar una aplicación de IA. Lo mismo puede ocurrir con una compañía no tan joven, pero aún de reducido tamaño, o con empresas más veteranas y de mayor dimensión, por el simple hecho de que nadie en ellas se haya ocupado de recoger metódicamente datos de su actividad y su mercado, entre otros. Estas posibles situaciones de escasez de datos impiden utilizar una aplicación de IA, pero, afortunadamente, para cada problema hay una solución: las empresas pueden comprar bases de datos de otras compañías y organizaciones (naturalmente, en función del marco legal aplicable, que en Europa es desfavorable en comparación con Estados Unidos). De hecho, existen empresas que actúan como intermediarias entre agentes que desean comprar o intercambiar datos.
Una cuestión citada en el tercer escalón de la escalera de inteligencia artificial –y controvertida– en relación a los datos es la presencia de sesgos, que puede generar resultados humana y socialmente injustos, como se ha podido comprobar en diversas ocasiones. Es fácil culpar a la IA por ello, pero la culpa no es de la herramienta, sino de quien le da el peor uso. Si alimentamos una aplicación de IA con datos que contienen sesgos, el resultado será sesgado. No obstante, frecuentemente, el sesgo es difícil de prevenir, y suele detectarse después de procesar millones de datos. En este aspecto, hay que reconocer que nuestra sociedad presenta sesgos indeseables, que quedan reflejados en los datos con los que alimentamos las aplicaciones de IA. Somos conscientes de ellos, los criticamos…, pero ahí están. Por ello, hay que ser muy cuidadosos con la información y, aun así, analizar los resultados de su proceso, por si hay que rectificarlos.
Existen numerosos casos en los que los resultados de las aplicaciones de IA presentan sesgos indeseables. La científica canadiense Joy Buolamwini, del MIT Media Lab, mientras preparaba un trabajo de investigación, descubrió que su rostro, de piel oscura, no era reconocido por una aplicación de IA de reconocimiento facial. Para seguir trabajando con ella, debía utilizar una máscara blanca. Analizó la aplicación para hallar qué era lo que fallaba, y descubrió que había sido “entrenada” con un gran número de imágenes de rostros de personas de piel clara. Los desarrolladores de la misma, en su mayoría hombres de piel clara, obviaron alimentar la aplicación con imágenes de personas con otros tonos de piel, además de incluir, por cierto, también una menor proporción de rostros de mujer. Esta discriminación –basura dentro– ocasionó un resultado sesgado –basura fuera–, tratándose de un ejemplo de total ausencia de rigor y sentido de la justicia en su desarrollo.
En otros casos, el sesgo puede no ser tan flagrante y aún persistir, a pesar de que se ponga mucha atención en evitarlo. Por ejemplo, la empresa norteamericana Pymetrics ofrece a las organizaciones unos videojuegos impulsados por IA para ser utilizados en sus procesos de selección de personal. Una de las versiones de esta aplicación ofrece como opción elegir entre juegos diseñados para personas con daltonismo, TDAH o dislexia, puesto que la legislación norteamericana prohíbe la discriminación por discapacidad o trastornos concretos en estos procesos. Ante ello, el “jugador” que presente una de estas afecciones, comprensiblemente dudará entre seleccionar o no la opción correspondiente. Si la selecciona, quedará clasificado como tal. Si no la selecciona, obtendrá, previsiblemente, un peor resultado en el uso del videojuego. ¿Como evitar este sesgo tan potencialmente perjudicial para el candidato? Pymetrics afirma que, para impedir discriminaciones, no informa a la empresa de los casos en que se ha seleccionado una de estas tres adaptaciones, sino que solamente comunica la puntuación obtenida con el videojuego. A pesar de ello, las dudas acerca del justo funcionamiento de esta herramienta pueden, lógicamente, persistir.
Finalmente, el sesgo puede ser consecuencia de no haber usado una variedad y cantidad de datos suficientes. Supongamos que se quiere utilizar una aplicación de IA para analizar la incidencia de plagas en cultivos de una variedad de cereal determinada. Para ello, se toman datos relativos a la altitud del terreno sobre el nivel del mar, la composición química del suelo, las temperaturas y la pluviosidad registradas, así como los abonos y plaguicidas empleados. Pero se obvia tomar datos acerca de la humedad ambiental, la dirección y fuerza del viento y los fenómenos meteorológicos extremos. Además, los datos tomados pertenecen a pocas explotaciones. Seguramente, el resultado obtenido será sesgado, al no haberse tenido en cuenta factores que pueden incidir en la presencia de plagas, y al no contar con una cantidad de datos sobre explotaciones suficientemente representativa de la realidad.
Segundo reto: implantación
Abrir cien millones de melones al mismo tiempo, verificar cuántos están buenos y cuántos no y por qué, puede no ser la mejor idea. Una empresa que consiga contar con una buena arquitectura de información puede tener la tentación de comenzar a aplicar la IA haciendo un uso exhaustivo de los datos disponibles, con el fin de obtener un ambicioso conjunto de resultados en diversos aspectos del negocio. Pero esta puede no ser la mejor idea, puesto que, en primer lugar, una buena arquitectura de información no es una perfecta arquitectura de información. Los datos no son 100% fiables, y, aun tras haber dedicado mucho tiempo y recursos a depurarlos, siempre puede haber errores y sesgos imprevistos, como se ha comentado. Por ello, no puede esperarse un perfecto funcionamiento de las aplicaciones de IA desde el primer momento. Hasta que no se hayan abierto y analizado unos cuantos “melones”, no se va a conocer el potencial que ofrecen los datos y las aplicaciones. Es mucho más recomendable, por tanto, comenzar con una aplicación y una cantidad limitada de información, observar y analizar el resultado obtenido e ir afinando y corrigiendo errores en base a ello. Y, cada vez que se consiga que una aplicación funcione correctamente con una cantidad determinada de datos, es aconsejable incrementar, de forma paulatina, la cantidad y variedad de datos y aplicaciones.
Una empresa que actualmente no esté usando ninguna aplicación de IA no tiene por qué sentir que hay un abismo entre ella y esta tecnología; ni siquiera por el hecho de tratarse, si es el caso, de una pequeña o mediana empresa. Podría pensarse que, para optar por el uso de IA en una empresa, es necesario acometer una gran inversión en software y hardware, así como contratar personal especializado y caro, y que todo ello no está al alcance de muchos, pero no es así necesariamente. Numerosos equipos de científicos y programadores, así como empresas tecnológicas, ofrecen soluciones y aplicaciones de IA mediante licencia, y la capacidad de procesamiento que no tengan los equipos de la compañía puede ser arrendada en la nube, a un coste razonable y adaptable a las necesidades de cada momento.
Tercer reto: incremento de productividad
Pasar de traducir unas cuantas frases del ruso al inglés (IBM, 1954) a traducir Guerra y paz, de Tolstói, en tres segundos (Microsoft, 2017) ha costado algo más de seis décadas. Y los traductores automáticos no obtienen todavía resultados impecables. Elon Musk declaró que sus nuevas megafactorías no tendrían operarios, confiando en que las tecnologías de IA y robótica se lo permitirían. Pero, un tiempo después, tuvo que admitir que el factor humano todavía es necesario y trabajará brazo (humano) con brazo (robótico), por lo menos en el corto y medio plazo. Y es que, a menudo, aquellas a las que denominamos “nuevas tecnologías” no son tan nuevas en el momento de alcanzar su uso generalizado. Tampoco su aplicación en las actividades empresariales genera inmediatamente un crecimiento de productividad espectacular. Según David Rotman, editor de MIT Technology Review, este crecimiento ha sido más bien decepcionante en los últimos veinte años, considerando el impresionante desarrollo de nuevas tecnologías que se ha registrado en el período1. El profesor de Stanford Erik Brynjolfsson describe este hecho como “la paradoja de la productividad”, sugiriendo que la simple aplicación de una nueva tecnología no garantiza un incremento de productividad. No obstante, Brynjolfsson reconoce que, posiblemente, esta tecnología no ha sido suficientemente aplicada como para generar un incremento de productividad notable, que espera que sí se produzca en los próximos años.
A veces es necesaria una crisis para ponerse las pilas. Buen ejemplo de ello es el rápido desarrollo de varias vacunas para la COVID-19 por parte de diferentes laboratorios biotecnológicos y farmacéuticos. Otro ejemplo es la adopción generalizada de herramientas para reuniones remotas que se ha producido durante la pandemia, que reducen desplazamientos y necesidad de espacio físico. Otro caso, más modesto y relativo a una tecnología de IA aún en desarrollo, lo encarna Abzu, con su aplicación de IA que identifica relaciones entre fuentes de datos, permitiendo efectuar predicciones precisas para acelerar el proceso de desarrollo de nuevos medicamentos.
Estos tres ejemplos sugieren que lo conveniente es afinar cuál es la tecnología óptima aplicable a cada objetivo de la empresa, buscando un resultado que conduzca eficazmente a un incremento de la productividad. Aunque esto puede no ser suficiente: como afirma Marianne Bellotti (U.S. Digital Service), en numerosas ocasiones, los procesos de toma de decisiones se apoyan menos en un análisis objetivo de los datos que en el resultado de una negociación entre las personas implicadas en ellos, que tienen diferentes prioridades y muestran distintos niveles de tolerancia al riesgo. Naturalmente, el factor humano no cede todo su protagonismo a la IA, al menos, por ahora.
Cuarto reto: La Paradoja de Polanyi o el problema de la Caja Negra
Brian Subirana, director de Inteligencia Artificial del Massachusetts Institute of Technology (MIT), explicaba en 2019 que, cuando su equipo desarrollaba una aplicación de IA, esta requería mucha actividad de prueba y error hasta conseguir que funcionara razonablemente bien; hasta el punto de que, una vez se obtenía ese buen funcionamiento, el equipo no podía explicar “por qué ahora funciona, y antes no lo hacía”. La paradoja de Polanyi2 se refiere a que los humanos somos capaces de hacer cosas que no sabemos explicar. El saxofonista que ejecuta una maravillosa improvisación; el futbolista que, regateando de forma increíble a cinco defensas, completa su proeza marcando un gol; el conductor que cambia de carril en la autopista porque adivina que el camionero que va por su derecha va a hacerlo sin usar el intermitente… Son habilidades que se adquieren con la práctica, y no a partir de un aprendizaje metódico o unas instrucciones muy concretas, y que no son fácilmente explicables a posteriori.
En el ámbito de la IA, este fenómeno recibe el apelativo de caja negra: algunas aplicaciones de IA aprenden en base a los datos que se les proporciona, toman sus conclusiones y ofrecen sus resultados, sin explicar cómo lo han hecho. Y ello puede representar algunos problemas para la compañía que toma y ejecuta decisiones basadas en el uso de aplicaciones de IA. Porque, en el mundo empresarial, así como en otros entornos, el rendimiento de cuentas es algo esencial. En algunas situaciones, especialmente en aquellas en las que algo ha salido mal, puede resultar muy comprometido pretender explicar que tal decisión fue aconsejada –o incluso, tomada– por una aplicación de IA en base a… algo desconocido. La red social china Tencent tuvo que retirar un chatbot en 2017, denominado BabyQ y desarrollado por Turing Robot, porque respondía con un seco “no” a la pregunta ¿te gusta el Partido Comunista Chino? Curiosidades aparte, especialmente en las actividades reguladas (banca, seguros, energía y otras), el fenómeno caja negra puede ser especialmente problemático, por razones obvias.
Pero este fenómeno también tiene su parte buena: nos recuerda que la IA no ha venido para sustituir al factor humano, sino para apoyarlo, y que este sigue siendo esencial en la toma de decisiones, su ejecución y el seguimiento de sus resultados. Aun así, algunos científicos y corporaciones tecnológicas (entre ellas, Google) están desplegando la denominada inteligencia artificial explicable (explanaible AI). En el caso de Google, los desarrolladores crearon una herramienta de este tipo (y la están ofreciendo actualmente a terceros) porque querían saber, una vez funcionaba, cómo lo hacían las aplicaciones de IA que desarrollaban y utilizaban en sus motores de búsqueda y en sus sistemas operativos para dispositivos móviles.
Quinto reto: nivel de desarrollo de las tecnologías de inteligencia artificial
No todas las tecnologías de IA han adquirido el nivel de desarrollo idóneo: las confusiones fatales de las aplicaciones de reconocimiento de imágenes de los coches autónomos, los asistentes de voz que dan respuestas políticamente incorrectas o el funcionamiento poco satisfactorio de buscadores y chatbots lo ilustran.
Aun así, muchas empresas desearían poder utilizar plenamente aplicaciones de reconocimiento de voz y de texto, asistentes virtuales, sistemas de reconocimiento de imágenes y otras herramientas para relacionarse con sus clientes, a la hora de realizar gestiones de información, asesoramiento, entregas y devoluciones, servicios posventa…, liberando a personal de estas tareas. Pero, para buena parte de estas funciones, estas aplicaciones, que funcionan con datos semiestructurados o no estructurados (imágenes, texto, comunicación oral), no ofrecen todavía un grado de fiabilidad suficiente. Esto puede ser comprobado frecuentemente al realizar preguntas al asistente de un teléfono inteligente y constatar que, en numerosas ocasiones, no comprende bien lo que se le está pidiendo. Por ello, las empresas deben ser muy prudentes en el uso de este tipo de aplicaciones, que pueden llevar a errores, quejas, reclamaciones e insatisfacción de los clientes.
Este funcionamiento imperfecto de las aplicaciones de IA, especialmente aquellas que trabajan con datos no estructurados, afecta no solamente a las empresas, sino también a actividades muy sensibles, como, por ejemplo, las funciones policiales. Como recogía una noticia de The New York Times3, en 2020 tuvo lugar la detención de un ciudadano norteamericano, Robert Williams, cuya orden fue activada erróneamente por una aplicación de reconocimiento de imágenes.
Contrariamente, las aplicaciones de IA que se basan en datos estructurados (datos numéricos bien organizados en una base) tienen un funcionamiento mucho mejor.
Algunas personas tienen la percepción de que las aplicaciones de IA son sustitutivas del talento humano; pero, al menos por ahora, no es así. Y no solamente por los errores que estas aplicaciones cometen. El escritor, editor y fotógrafo Kevin Kelly explica que la biología no es fácilmente replicable, y que la forma en la que pensamos los humanos es distinta a la forma en la que opera una aplicación de IA, del mismo modo que la forma en la que vuela un avión es diferente a la forma en la que lo hace un pájaro. Por lo tanto, la IA no puede sustituir al humano, sino que lo que hace es aumentar sus capacidades.
Sexto reto: rechazo social y laboral
Un fabricante de la ciudad inglesa de Huddersfield recibió en 1812 una carta firmada por un tal Ned Ludd, que le decía: “Hemos sabido que usted es el propietario de estas detestables máquinas de hilar, y mis hombres me han solicitado que le advierta de que tiene que destruirlas (…)”. El falso firmante de esta carta dio nombre al movimiento ludista, que rechazaba la sustitución de mano de obra humana por máquinas, y que protagonizó actividades violentas en el siglo XIV. La IA no genera un rechazo tan violento, sino, en todo caso, críticas, algo de prevención e incluso algún temor. El mismo Elon Musk afirmó en 2018 que la IA es más peligrosa que el armamento nuclear. En este aspecto, el famoso emprendedor no parece tener muchos seguidores, puesto que a la vista está la tranquilidad con la que miles de millones de personas ceden sus datos personales, gustos y opiniones a grandes empresas, a cambio de disfrutar de unos minutos de ocio, de satisfacer su curiosidad, de intercambiar opiniones y, posiblemente, de ejercer su vanidad. Aun así, Musk ha presentado recientemente su proyecto de robot humanoide, y ha resaltado que una de sus especificaciones es que “podrás huir de él”, en alusión a la baja velocidad a la que caminará.
Por un lado, puede existir una percepción mágica de lo que es la IA, alimentada por novelas y películas de ciencia ficción, con una visión trágica en la que las máquinas toman el control de la humanidad. Por otro lado, una percepción más práctica, realista y con sensibilidad social, en la que la preocupación por el futuro de los puestos de trabajo y por la privacidad de las personas es el principal elemento. Las revoluciones tecnológicas que la humanidad ha vivido en el pasado y la que vive ahora han comportado y comportan la reducción –o incluso la desaparición– de puestos de trabajo, para crear otros de distinta naturaleza. Como Kevin Kelly sugiere, el descendiente de un jornalero de la época anterior a la revolución agraria es hoy un especialista en marketing digital, y, probablemente, su nieto tendrá una profesión que hoy no conocemos todavía. Las voces más optimistas afirman que esto seguirá ocurriendo del mismo modo, y es más que comprensible la preocupación de muchas personas, que temen perder sus puestos de trabajo sin estar preparadas para acceder a nuevas ocupaciones, ya que estas requieren unos niveles de conocimientos técnicos que ellos no poseen ni pueden alcanzar en el corto o medio plazo.
Es por ello que las empresas, al incorporar aplicaciones de IA, deben estar preparadas para responder a la preocupación que, sin duda, mostrarán buena parte de sus trabajadores. Asimismo, las instituciones educativas públicas y privadas deberán proveer a la ciudadanía de la posibilidad de estudiar y prepararse para estas nuevas profesiones del futuro, y la ciudadanía deberá estar dispuesta a seguir aprendiendo y aceptando nuevos retos.
La destrucción creativa de puestos de trabajo no representa ahora mismo una urgencia social, pero puede serlo en un futuro no muy lejano, puesto que todo parece indicar que esta revolución tenderá a acelerarse en los próximos años.
Séptimo reto: confianza
Además de la prevención y el temor acerca de la IA en general, es necesario tener presentes sus versiones particulares; es decir, las que pueden surgir en el momento en el que un cliente o usuario conoce o sospecha que está interactuando con una aplicación de IA. Cualquier sistema sustentado en aplicaciones de IA debe ofrecer el máximo nivel de confianza posible, no solamente para despejar estas dudas, sino para que resulte realmente útil y justo. Para ello, las empresas y organizaciones que utilicen estas aplicaciones deben ser capaces de ofrecer:
• Trazabilidad. Los desarrolladores de aplicaciones de IA deben poder proporcionar mecanismos de trazabilidad de los algoritmos presentes, a fin de localizar y corregir sesgos y otros aspectos no deseables, que puedan surgir en el uso de estas aplicaciones. Ya han sido explicadas las dificultades que ello conlleva y los esfuerzos de varios actores del sector para mejorarla.
• Privacidad. Los datos de los clientes y usuarios deben estar siempre protegidos, y su uso debe responder fielmente a las condiciones contractuales con las que hayan sido obtenidos. Los marcos legales según países aplican distintos grados de protección de estos datos.
• Ausencia de sesgos. Los datos usados para adiestrar a las aplicaciones de IA no deben contener sesgos, y estas aplicaciones deben ser periódicamente auditadas para detectarlos, en su caso. Asimismo, se debe estar razonablemente seguro de que se nutre a la aplicación de la cantidad, variedad y calidad de datos más exigentes.
• Ética. Es posible que la Dirección de una compañía afirme “Nosotros estamos aquí para ganar dinero” o, más políticamente correcto, “Nuestro compromiso es mantener los puestos de trabajo, de los que dependen muchas familias”. Pero, afortunadamente, cada vez más, se espera que las empresas expresen, compartan y actúen en función de valores éticos
y de justicia social.